Abstract
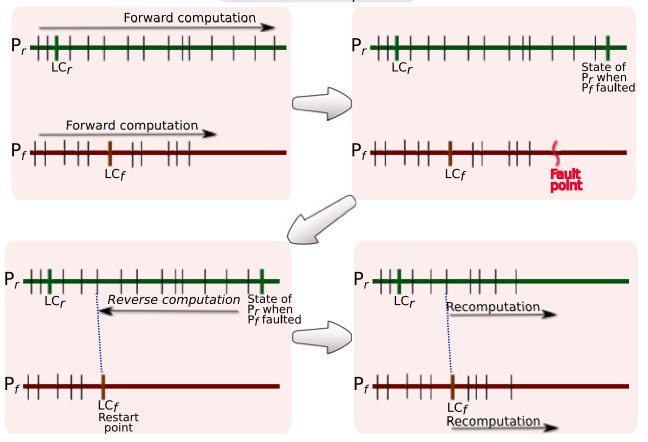
Reverse computation is presented here as an important future direction in addressing the challenge of fault tolerant execution on very large cluster platforms for parallel computing. As the scale of parallel jobs increases, traditional checkpointing approaches suffer scalability problems ranging from computational slowdowns to high congestion at the persistent stores for checkpoints. Reverse computation can overcome such problems and is also better suited for parallel computing on newer architectures with smaller, cheaper or energy-efficient memories and file systems. Initial evidence for the feasibility of reverse computation in large systems is presented with detailed performance data from a particle (ideal gas) simulation scaling to 65,536 processor cores and 950 accelerators (GPUs). Reverse computation is observed to deliver very large gains relative to checkpointing schemes when nodes rely on their host processors/memory to tolerate faults at their accelerators. A comparison between reverse computation and checkpointing with measurements such as cache miss ratios, TLB misses and memory usage indicates that reverse computation is hard to ignore as a future alternative to be pursued in emerging architectures.
Kalyan Perumalla
Kalyan Perumalla is a computer scientist focused on research in supercomputing, quantum computing, and artificial intelligence, as research staff member, faculty, and program manager with the U.S. government, national labs, and universities. As a Federal Program Manager in Advanced Scientific Computing Research at the U.S. Dept. of Energy, Office of Science, He managed a $100-million R&D portfolio covering AI, HPC, Quantum, SciDAC, and Basic Computer Science. In his 25-year R&D leadership experience, he previously led advanced R&D as Distinguished Research Staff Member at the Oak Ridge National Laboratory (ORNL) developing scalable software and applications on the world’s largest supercomputers for 17 years, including as a line manager and a founding group leader. He has held senior faculty and adjunct appointments at UTK, GT, and UNL, and was an IAS Fellow at Durham University.