Abstract
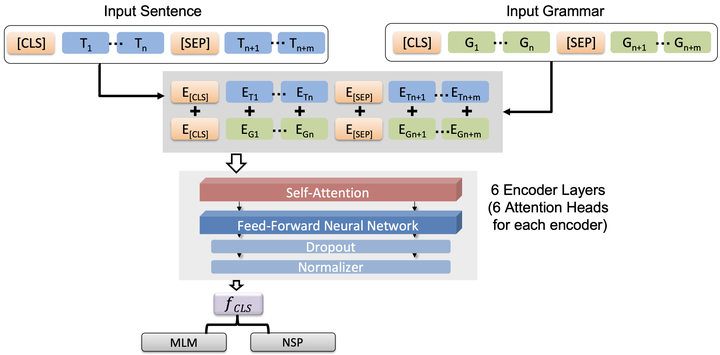
Machine Learning and Natural Language Processing are playing an increasingly vital role in many different areas, including cybersecurity in Information Technology and Operational Technology networking, with many associated research challenges. In this paper, we introduce a new language model based on transformers with the addition of syntactical information into the embedding process. We show that our proposed Structurally Enriched Transformer (SET) language model outperforms baseline datasets on a number of downstream tasks from the GLUE benchmark. Our model improved CoLA classification by 11 points over the BERT-Base model. The performance of attention-based models has been demonstrated to be significantly better than that of traditional algorithms in several NLP tasks. Transformers are comprised of multi attention heads stacked on top of each others. A Transformer is capable of generating abstract representations of tokens input to an encoder based on their relationship to all tokens in a sequence. Despite the fact that such models can learn syntactic features based on examples alone, researchers have found that explicitly feeding this information to deep learning models can significantly boost their performance. A complex model like transformers may benefit from leveraging syntactic information such as part of speech (POS).
Kalyan Perumalla
As a Federal Program Manager in Advanced Scientific Computing Research at the U.S. Dept. of Energy, Office of Science, Kalyan Perumalla manages a $100-million R&D portfolio covering AI, HPC, Quantum, SciDAC, and Basic Computer Science. In his 25-year R&D leadership experience, he previously led advanced R&D as Distinguished Research Staff Member at the Oak Ridge National Laboratory (ORNL) developing scalable software and applications on the world’s largest supercomputers for 17 years, including as a line manager and a founding group leader. He has held senior faculty and adjunct appointments at UTK, GT, and UNL, and was an IAS Fellow at Durham University.