Abstract
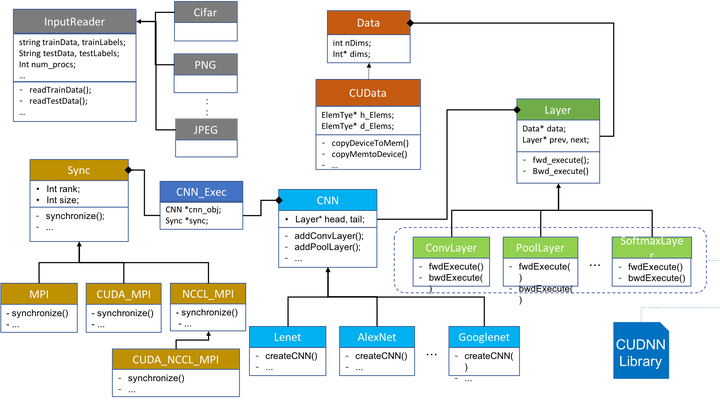
Large parallel machines generally offer the best parallel performance with ’native execution’ that is achieved using codes developed with the optimized compilers, communication libraries, and runtimes offered on the machines. In this paper, we report and analyze performance results from native execution of deep learning on a leadership-class high-performance computing (HPC) system. Using our new code called DeepEx, we present a study of the parallel speed up and convergence rates of learning achieved with native parallel execution. In the trade-off between computational parallelism and synchronized convergence, we first focus on maximizing parallelism while still obtaining convergence. Scaling results are reported from execution on up to 15,000 GPUs using two scientific data sets from atom microscopy and protein folding applications, and also using the popular ImageNet data set. In terms of the traditional measure of parallel speed up, excellent scaling is observed up to 12,000 GPUs. Additionally, accounting for convergence rates of deep learning accuracy or error, a deep learning-specific metric called ’learning speed up’ is also tracked. The performance results indicate the need to evaluate parallel deep learning execution in terms of learning speed up, and point to additional directions for improved exploitation of high-end HPC systems.
Kalyan Perumalla
As a Federal Program Manager in Advanced Scientific Computing Research at the U.S. Dept. of Energy, Office of Science, Kalyan Perumalla manages a $100-million R&D portfolio covering AI, HPC, Quantum, SciDAC, and Basic Computer Science. In his 25-year R&D leadership experience, he previously led advanced R&D as Distinguished Research Staff Member at the Oak Ridge National Laboratory (ORNL) developing scalable software and applications on the world’s largest supercomputers for 17 years, including as a line manager and a founding group leader. He has held senior faculty and adjunct appointments at UTK, GT, and UNL, and was an IAS Fellow at Durham University.