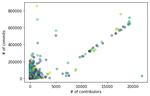
We present preliminary results from characterizing the distribution of 452 million commits in a metadata listing from GitHub repositories. Based on multiple distributions, we find the best fits and second best fits across different ranges in the data. The characterization is aimed at synthetic repository generation suitable for use in simulation and machine learning.