ZeroIn: Characterizing the Data Distributions of Commits in Software Repositories
Abstract
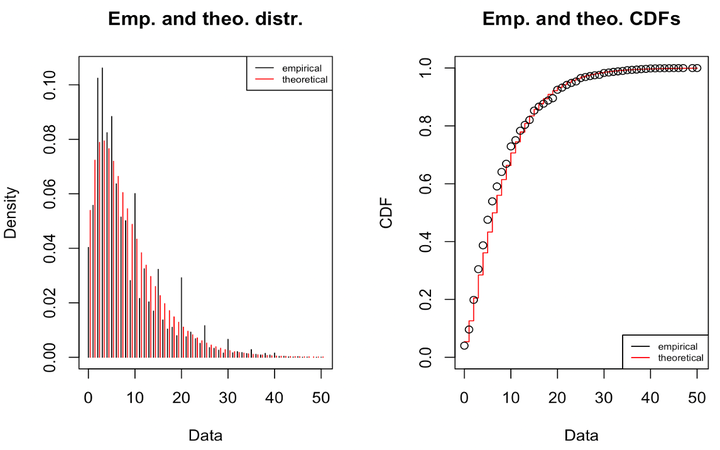
Modern software development is based on a series of rapid incremental changes collaboratively made to large source code repositories by developers with varying experience and expertise levels. The ZeroIn project is aimed at analyzing the metadata of these dynamic phenomena, including the data on repositories, commits, and developers, to rapidly and accurately mark the quality of commits as they arrive at the repositories. In this context, the present article presents a characterization of the software development metadata in terms of distributions of data that best captures the trends in the datasets. Multiple datasets are analyzed for this purpose, including Stack Overflow on developers’ features and GitHub data on over 452 million repositories with 16 million commits. This characterization is intended to make it possible to generate multiple synthetic datasets that can be used in training and testing novel machine learning-based solutions to improve the reliability of software even as it evolves. It is also aimed at serving the development process to exploit the latent correlations among many key feature vectors across the aggregate space of repositories and developers. The data characterization of this article is designed to feed into the machine learning components of ZeroIn, including the application of binary classifiers for early flagging of buggy software commits and the development of graph-based learning methods to exploit sparse connectivity among the sets of repositories, commits, and developers.
Kalyan Perumalla
Kalyan Perumalla is a computer scientist focused on research in supercomputing, quantum computing, and artificial intelligence, as research staff member, faculty, and program manager with the U.S. government, national labs, and universities. As a Federal Program Manager in Advanced Scientific Computing Research at the U.S. Dept. of Energy, Office of Science, He managed a $100-million R&D portfolio covering AI, HPC, Quantum, SciDAC, and Basic Computer Science. In his 25-year R&D leadership experience, he previously led advanced R&D as Distinguished Research Staff Member at the Oak Ridge National Laboratory (ORNL) developing scalable software and applications on the world’s largest supercomputers for 17 years, including as a line manager and a founding group leader. He has held senior faculty and adjunct appointments at UTK, GT, and UNL, and was an IAS Fellow at Durham University.